It’s not just you: Writing code is way more fun than reading it! Taking the time to read, process and understand a piece of code let alone a codebase can take heaps of work.
That said, as codebases grow in size and complexity, as dependencies increase and adapt over a project’s lifetime, it becomes significantly more cumbersome to effectively read them, but at the same time all the more important to keep track of where critical pieces of functionality lie.
Why read code?
Seeing the ways different folks go about solving different problems helps add perspective to our problem-solving approaches.
What cemented this for me was my experience as a kids’ coding coach. The way they have fewer assumptions of how code should work really helped me appreciate different folks’ experiences and try out new thought processes.
Building with our knowledge being exposed to that of others is one of the fundamentals behind the theory of elementary learning called constructionism, which is that of using the context of our understanding to build mental models and building upon them with others. It argues that the media through which we learn is just as important as the learning itself. By being exposed to the code of others, it influences the code that we write.
Here are some techniques I’ve picked up over the years to effectively read code:
Go through the dependencies
Is your codebase a JavaScript one? Let’s open up the package.json file. See some dependencies you recognize? React, Vue, Svelte, perhaps? It also helps to see what scripts are available. What does the build process look like, seeing that we’re using, say, Babel or ESBuild?
Looking at this information can tell us a lot about what to expect when understanding a codebase. For example, some things I’ll look at include, say if it’s a web app, what version of Webpack is being used? Is Webpack being used at all instead of, say, Rollup? What version of Node.js is required? Is it running React version 16 or 17?
We can try the same for the Gemfile if it’s a Ruby codebase, or the Cargo.toml one if written in Rust. This is a great entry point for seeing what makes a codebase tick!
Run the code
This might seem counterintuitive if we’re trying to read the code, but in my experience I find that just doing the work to get the code up and running, debug any issues that might come up with trying to get it running locally for me helps loads with understanding what the code is doing.
It’s possible that trying to run the code will throw up an error. Maybe it’s because we’re trying to run the code on an unexpected setup, or a less-supported web browser. This could even lead to finding unintended issues. Focusing in on these areas helps to build a mental model of what’s going on in a codebase.
It’s also possible that the code will run on the first try, and we can jump right in and start testing specific parts of it. Here, we can use our debugging system, be it the browser’s devtools (as seen on Firefox or Chrome), LLVM for native apps, or using breakpoints in our IDE (I still do plenty of print statement debugging, myself!) to navigate calls made by the codebase during running and see how it all fits together. Stepping through the code by trying out functionality and debugging helps us understand how these pieces fit together, too!
This is an angle of understanding we’re aiming to tackle at CodeSee, letting you record which sections of your code get called up.
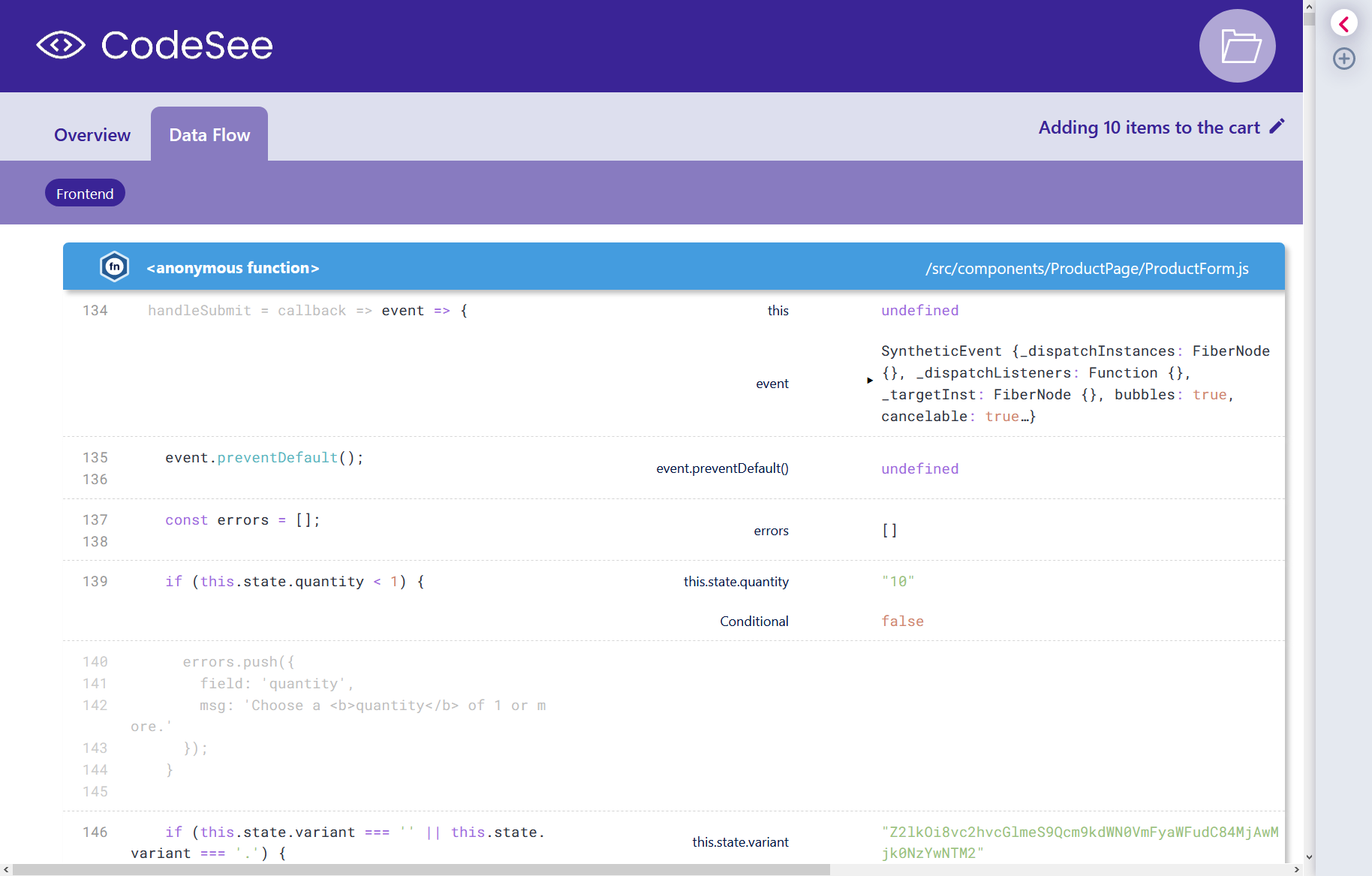
Checking out the test suite
A well written test suite should give you a bird’s eye view of what a specific module or functionality set is meant to do. The test author is essentially telling us what they expect the implementation being tested to do. We can use this as a basis for building an understanding of that module.
I find it helps to first take a look at any feature/system tests and then narrow down into individual modules’ unit tests, depending on whether these are available of course. Your mileage may vary, of course. I tend to opt for an outside-in approach.
It does happen that some parts of a codebase will be missing testing coverage. This is a good opportunity to try writing some. Let’s say, for example, we have a module called NumberToHex that converts decimal numbers to hexadecimal. It is, however, untested. This is an opportunity for us to write some tests, understanding what we expect this converter to do, to test that 5 will be converted to 5, that 10 will be converted to 16, and so on.
This can motivate us to try and look at, say, a module, and how we can unit test it effectively, building that understanding. And hey, this also can be a handy contribution to that codebase!
Piecemeal refactoring
To be clear, this is by no means a suggestion to rewrite an entire module, codebase, or anything like that! But if a piece of code is proving hard to read for you, maybe doing a quick refactor can help with understanding it. If there are tests to support you along the way (or that you wrote, see the previous section), all the more safer the feeling!
Doing things like breaking down a large function into smaller ones can go very far toward helping understanding a piece of code much better!
Pairing
If someone who is familiar with a particular piece of code is available, there’s no loss in asking them to walk you through it! Benefits go both ways:
As the person guiding someone through the code, articulating the decisions made towards it helps improve the understanding of the code you wrote.
As the person being guided, you have a great opportunity to ask questions, offer constructive feedback, and even work on a contribution together!
And those are just some techniques!
Regardless of your level of experience, taking the time to read others’ solutions can go a long way towards boosting your understanding of a codebase. Following are some other points of view on the same topics that helped shape some of the above ideas, from Alan Skorkin and Mathis Garberg.
Ultimately, being exposed to different problem-solving styles helps us grow as software builders. But we’d love to hear from you! Do you have any techniques you’ve picked up for making the code-reading process smoother? Hit us up!