🏗️ Projects
Browse through open source projects on OpenSourceHub.io, add your project to get more exposure and connect with other maintainers and contributors!
🍉 Watermelon DB
A reactive database framework which lets you build powerful React and React Native apps that scale and remain fast
language: JavaScript, stars: 8857, last commit: 2 days
repo: github.com/Nozbe/WatermelonDB
👾 Ruffle
Ruffle is an Adobe Flash Player emulator written in the Rust programming language. Ruffle targets both the desktop and the web using WebAssembly.
language: Rust, stars: 11321, last commit: Today
repo: github.com/ruffle-rs/ruffle/
site: ruffle.rs
📊 pytest
The pytest framework makes it easy to write small tests, yet scales to support complex functional testing
language: Python, stars: 9705, last commit: April 20, 2022
repo: github.com/pytest-dev/pytest
site: pytest.org
✨ git-cliff
git-cliff is a changelog generator that can generate changelog files from the Git history by utilizing conventional commits as well as regex-powered custom parsers.
language: Rust, stars: 5066, last commit: Today
repo: github.com/orhun/git-cliff
site: git-cliff.org
Join thousands of other open-source enthusiasts and developers in the Open Source Hub Discord server to continue the discussion on the projects in this week's email!
🎙️ Interview With Orhun of git-cliff

Hey Orhun! Thanks for joining us! Let us start with your background.
Hey! My name is Orhun Parmaksız and I’m from Turkey. As long as I knew myself, I was always interested in tech/programming and my first project was a custom flip-flop circuit that I programmed using C with a PIC16F64A microcontroller when I was a kid. In my early years, I mostly worked on DIY electronic projects and low-level/embedded programming. Later on, I expanded my hobby by learning different programming languages and technologies, and eventually my path was crossed with Linux/open source. Ever since then, I've contributed to open source by sharing my own projects or getting involved in the projects that I like. For a couple of years, I’ve been writing Rust and I’m working on building a sustainable open source career for myself and pursuing open source full-time.
Industry-wise, I’m studying software engineering and I have worked at different companies as a Rust/Backend Engineer or DevOps. I really enjoy writing Rust so I have experience in building highly scalable backend services using frameworks such as Rocket, Axum, and Actix. My favorite projects are mostly CLI tools that are written in Rust since I need blazingly fast speeds in the terminal. I’m also the author of a couple of them, including git-cliff!
Who or what are your biggest influences as a developer?
Since I’m active in the open source community, there are a couple of really good Rust developers who inspire me to become better and work harder. If I were to give a couple of names: dtolnay, burntsushi, and fasterthanlime. Each of these people has a couple of significant achievements (such as writing a core tool/library or managing to live off of open source) and seeing them would make me feel one step closer to my "open source grindset" goal every day.
I also get influenced by different forms of media as well. For example, discovering new music or reading a decent book would help me solve problems since contributing to open source is often a creative process. Since you need to take advantage of your creativity for such cases, consuming visual/auditory art really helps.
What’s your most controversial programming opinion?
I believe the programmers who don’t code in their spare time and don’t contribute to open source will never become as good as those that do.
Success is a relative thing, but for me, I don’t think you can be successful if you treat programming as just a job and work 9-5. The true way of achieving things would be putting extra time into fiddling with ideas, learning, and building things. Open source really helps with achieving this since it provides a way for constant learning and self-improvement.
What is your favorite software tool?
I think one of the benefits of open source is that you can experiment with different tools and there are usually a lot of them. But for now, I want to answer this question with my current-favorite text editor: neovim. I’m not a long-time user of it, but a couple of months ago I switched to it and I really enjoy the extensibility. I love how lightweight and fast it is compared to the bloated IDEs that I used to use. It makes me motivated and makes building software more fun for sure!
If I gave you $10 million to invest in one thing right now, where would you put it?
I would most likely use that money as a resource to get one of my open source projects off the ground. I would build a better interface for everyone to use, set up a proper support system and improve the marketing. At the end of the day, I would simply work on building a foundation for a sustainable income from open source and being more apparent in the media. Sounds a bit delusional but I’m seeing a lot of great open source projects that are not being used since they stay obscure on GitHub.
What are you currently learning?
I’m currently reading/learning about core Linux topics like random number generation and also custom userspace implementations of protocols like D-Bus and IPC/sockets. That’s because my main interest is mostly low-level programming and Linux. I’m also a package maintainer at Arch Linux and it makes me able to dive deep into these topics.
In addition to those, I started to hear more about Zig in the last couple of months and I’m planning to learn it in depth by creating a project soon!
Why was git-cliff started?
When I was working on gpg-tui last year, the idea of having a proper changelog for the project struck me before releasing the first version. I am a big fan of Conventional Commits & Semver and I thought it would be awesome to quickly generate a changelog from my commits/tags. Eventually, I found myself deep in GitHub, looking for a changelog generator tool that will fit my needs. I tried a couple of tools, the first one being jilu, and unfortunately, I couldn’t customize it the way I wanted. I kept looking around and came across cocogitto which contains small tools for checking commits, generating changelogs, and all sorts of other semver related operations. However, most of the tools at the time were not suitable for my use case. So I decided to write my own!
My initial idea was to create a changelog generator that parses conventional commits and categorizes them by their scope and generates a changelog by utilizing a template engine. Later on, I added regex-powered commits parsers and preprocessors for customizing the generated changelog as much as possible.
How does git-cliff generate changelogs?
We can split the changelog generation mechanism into 3 parts as shown in the following high-level overview:
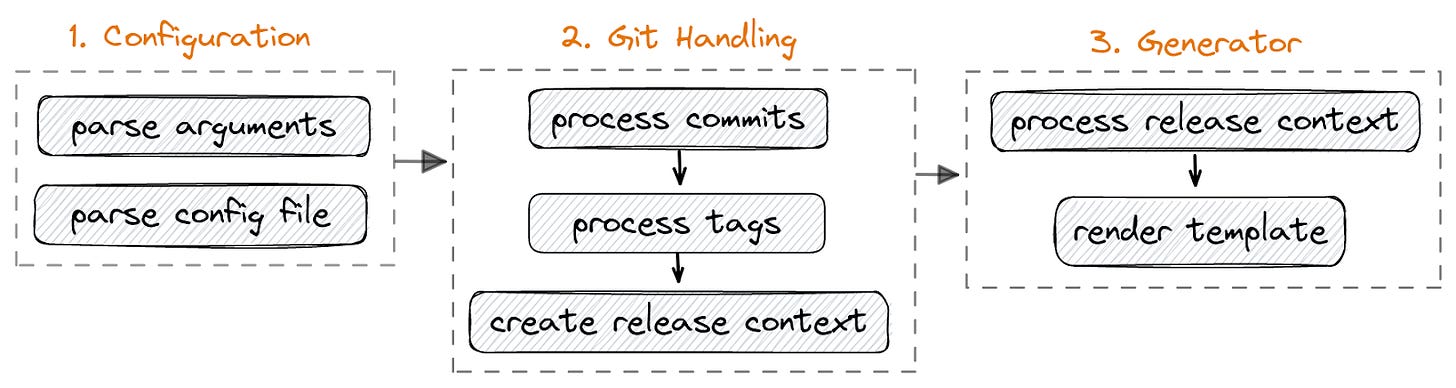
1. Configuration: First, we need to parse the command-line arguments and the configuration file. The importance of this step is that we need to uniform these two in order to have a final configuration. We also check the validity of the regex values and other configuration values in this step.
2. Git Handling: The core library of git-cliff handles opening the repository and retrieving the commits/tags based on the given configuration. This step involves e.g reading a certain part of the commit history, sorting the tags topologically, or skipping certain commits/tags. In the end, we iterate through each commit and tag for creating our so-called ‘release context’. A release context is a Rust struct that holds information about each individual release of the project. These objects will be fed into the changelog generator for rendering the template in the next step.
3. Generator: We utilize the release contexts that are created in the previous step and generate our changelog with the help of a template engine.
How is git-cliff implemented?
I would like to answer this question with an example.
Let’s say we want to write a minimal version of git-cliff, then we can do the following:

In the code above, we “open” the repository using git2 crate, create a traverser for the commits and configure it to start from HEAD.
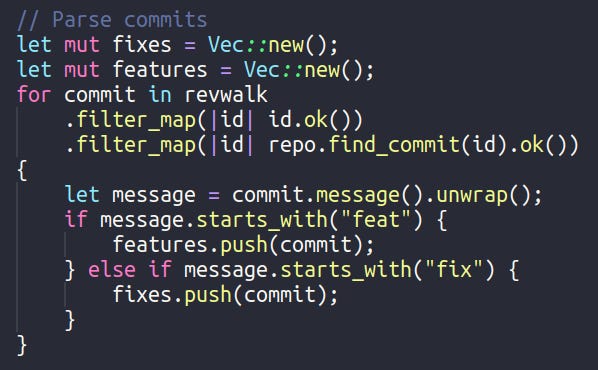
For the next step, we create 2 vectors for fix and feature commits. We iterate through the commit list and categorize the commits based on their prefix.
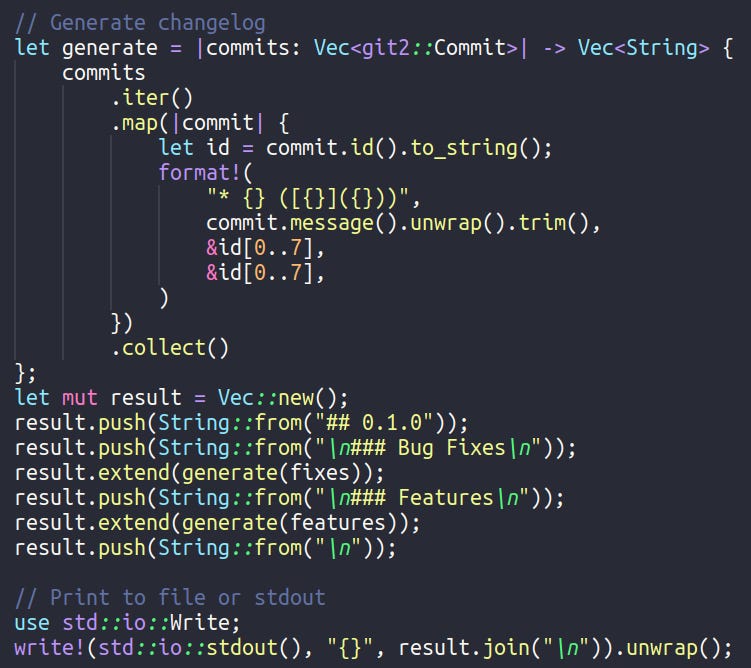
Next, we define an inline function named “generate” for generating separate parts of the changelog as “Bug Fixes” and “Features”. And finally, we pretty-print the result.
For the following Git history:
* 3d43b91 fix: fix Z feature
* 7d61dfa feat: add Y feature
* cc93e04 feat: add X feature
We get this result:
## 0.1.0
### Bug Fixes
* fix: fix Z feature ([3d43b91](3d43b91))
### Features
* feat: add Y feature ([7d61dfa](7d61dfa))
* feat: add X feature ([cc93e04](cc93e04))
There you go, you just got a simple changelog generator! Full code is available on this gist.
Why did you pick Rust?
I think Rust is a very suitable programming language for building command-line tools. First of all, it is fast due to code optimizations. Well, you might ask if we really need speed while generating changelogs. The answer is, yes, there are a lot of big repositories with thousands of commits and no one wants to wait a certain amount of time for such a trivial task. Currently, generating a changelog from the Linux kernel repository with the default config takes 123 seconds. (123 commits/123 tags)
Another important point is, Rust is memory/thread safe and this is something to consider when it comes to CLI tools.
Apart from technical points, Rust has a wonderful community, extensive documentation, great build tools, and an easy-to-adapt ecosystem. At the end of the day, it makes building stuff really fun and worthwhile.
What does cliff mean in the name git-cliff?
Ever since I started creating open source projects, I took the responsibility of handling the user-facing tasks of the project as well. This includes marketing the project, sharing it on various platforms, reaching out to people, advertising its features, and most importantly designing a logo. That’s why I start thinking about the name of the project and the logo early in the development phase and sometimes before I even start working on the project. With this motivation, after I completed the MVP of the project, I came up with the name git-cliff and its logo. The reason why I used “cliff” is that while I was browsing artwork for inspiration, I came across a couple of really nice mountain images and for some reason I like mountains. When you look at the top, it feels quiet and peaceful up there. It just makes me feel good. Same with the cliffs.
So I combined these two words and made it “git-cliff”. I think it sounds cool!
Who, or what was the biggest inspiration for git-cliff?
My biggest motivation was to have a simple enough changelog generator tool that I can quickly integrate into my project development workflow. With this thought in mind, I tried to keep everything simple and clean as much as possible. This also made it possible to develop git-cliff in a fast manner, and development was reactive enough to solve reported bugs and implement new features quickly.
Are there any overarching goals of git-cliff that drive design or implementation? If so, what trade-offs have been made in git-cliff as a consequence of these goals?
There aren't many overarching goals of git-cliff except which conventional commit parser to use. When I started implementing the parser for commits, I went ahead with git-conventional. Later on, I had the option to switch to conventional-commit-parser which is another parser library but I decided to move on with git-conventional since it was actively maintained.
See this issue for more discussion: https://github.com/orhun/git-cliff/issues/28
What is the most challenging problem that’s been solved in git-cliff, so far?
The most challenging issue that I had with git-cliff was actually something recent.
In April 2022, GitHub announced a security vulnerability about Git (CVE-2022-24765) which affects users working on multi-user machines where a malicious actor could create a .git directory in a shared location above a victim’s current working directory. This would cause all git invocations that occur outside of a repository to read its configured values. The problem is, some Git configuration values such as “core.fsmonitor” allows executing arbitrary commands and this can lead to arbitrary command execution when working on a shared machine.
In order to avoid this vulnerability, we can simply upgrade Git to 2.35.2. This version made some changes to Git’s behavior so when looking for a top-level .git directory, the traversal stops when the ownership changes from the current user. Git also made it possible to add exceptions via safe.directory configuration value.
Well, how does this affect git-cliff? In the Docker image (which is widely used in CI), when you try to run git-cliff, you would get this:
ERROR git_cliff > Git error: `config value 'safe.directory' was not found; class=Config (7); code=NotFound (-3)
Related issue: https://github.com/orhun/git-cliff/issues/108
To avoid this in the Docker container, I came up with the following workaround:
- Create a custom user (git-user)
- Configure a safe directory somewhere (/git-home/app)
- When you run the container, copy the contents of the project files to the safe directory with an entrypoint script
- Run git-cliff in the safe directoryI implemented this workaround in this commit: https://github.com/orhun/git-cliff/commit/4fc2217868fceea81ab5e6aeeb63ca719a07fe91
However, one day later, someone else reported this issue: https://github.com/orhun/git-cliff/issues/109
“The error is caused by the change of directory and ownership + enabling safe directory in the Dockerfile by default in 4fc2217”
The problem was, they were using the git-cliff container in GitLab CI which simply spawns the container shell as root user. Since git-cliff container is supposed to be run as a custom user (git-user), they were getting the same error that we are familiar with:
ERROR git_cliff > Git error: repository path '/builds/project/path is not owned by current user; class=Config (7); code=Owner (-36)
My solution was apparently removing the custom user and safe directory configuration from the Dockerfile. This would make it possible to run the container as any user without needing to worry about CVE-2022-24765. In the end, my workaround was reduced to: - With an entrypoint script, copy the contents of the project files to the working directory to change permissions when the container is being run
See my comment for detailed reasoning/explanation: https://github.com/orhun/git-cliff/issues/109#issuecomment-1256998189
Are there any projects similar to git-cliff? If so, what were they lacking that made you consider building something new?
I would say cocogitto is the most similar project to git-cliff. As I mentioned earlier, it is not actually lacking features but it has more diverse features such as auto-bump. It makes it possible to run certain hooks, create a version and generate a changelog whereas git-cliff only focuses on generating a highly customizable changelog based on the regex-parsed conventional commits and other various parameters defined in the configuration file.
Simply put, the main reason why I decided to build git-cliff after trying out other tools was the fact that I wanted to have something simpler.
What was the most surprising thing you learned while working on git-cliff?
I surely have learned a ton about Git internals and how Git works in general. On top of that, thanks to the contributors, there are a lot of Rust development tricks that I adopted. Apart from all these, I think creating test fixtures via GitHub Actions was a pretty neat solution by kenji-miyake. I surely didn’t know that you can reuse workflows via composite actions!
What is your typical approach to debugging issues filed in the git-cliff repo?
Most of the issues reported to the repository are either specifically about Git or edge cases which would push git-cliff to its limits to fit a certain use case. Thus I usually reproduce the issue by creating an empty repository and dummy commits. For example, the typical process is the following:
git init
git checkout -b develop
git commit --allow-empty -m "feat: v1.0.0"
git tag v1.0.0
git checkout -b master
git commit --allow-empty -m "chore: start work on v1.1.0"
…
Then I run git-cliff in this repository, reproduce the issue and fix it if possible.
What is the release process like for git-cliff?
I use git-cliff for the release process of git-cliff. I have a script called release.sh which is responsible for:
- Bump the versions in certain files including Cargo.toml
- Generate a changelog via git-cliff and update CHANGELOG.md
- Create a release commit
- Create a tagSo I only run the following commands for releasing a new version:
./release.sh v1.0.0
git push
git push --tags
The rest is handled with a GitHub Actions workflow which is responsible for creating binary archives for the GitHub release, building the Debian package, publishing on NPM, and publishing the crates.io package.
I also use git-cliff-action for generating a changelog for the GitHub releases.
Is git-cliff intended to eventually be monetized?
Yes, I’m planning to eventually provide premium/enterprise plans after I get some feedback from regular users about this idea. I think it would be cool to have extra plans for people who customize git-cliff in a particular way and need support with it. Of course, there is a long road ahead and we will see where the wind will take us. I will keep improving git-cliff until then and afterwards!
What are you most proud of?
TL;DR: I got a job in the largest tech company in my country thanks to git-cliff.
In September 2021, there was a huge increase in the number of stars in the repository. In less than a day, 1.2k people starred the repository and it kept rising after that. This was due to a HackerNews post making it to the first page and people getting interested in the project.
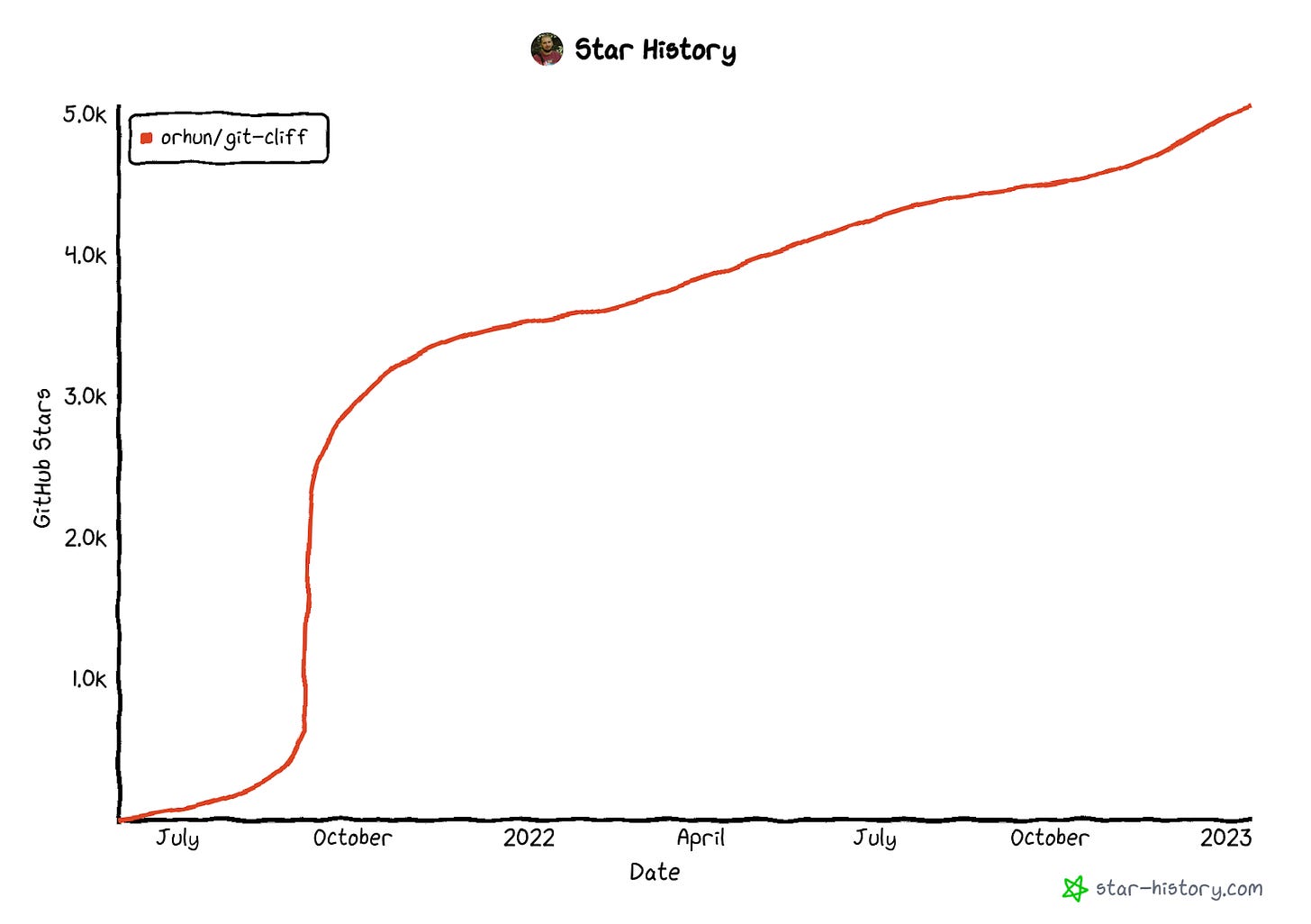
In the following days, I got interview requests from the largest companies in my country and they were also saying that they saw my profile from GitHub. Even a couple of my friends told me that their managers heard about the project and asked if they knew me or not. It was a wild time.
Fast-forward to the future, I decided to give a shot at a big company, eventually passed all the interviews, and eventually started working there. Interestingly enough, a part of my job was to integrate git-cliff to their release process.
To this day, I’m proud of the project and how it turned out. Open source is a powerful thing.
How do you balance your work on open-source with your day job and other responsibilities?
Not gonna lie, it is pretty hard sometimes. Especially if you are still studying like me and working on several different projects, your priorities get mixed after some point. However, although this is not healthy, I make sacrifices from my sleep and social life and eventually get things done. I’m still trying to find the perfect balance between everything and it’s unsurprisingly difficult. My trick is to think ahead of time and prioritize the most effective task that will affect me in a positive way in the semi-long term. Also, time management and multitasking are important skills to improve I believe.
Have you ever experienced burnout? How did you deal with it?
Of course. I experience burnout in a timely manner (every couple of weeks) and each time I’m getting better at coping with it. Recently, my trick is to do nothing in the matter of software and consume different types of art/media. For example; I watch a movie, read a classic book, or just explore new music. This way, I can take my mind off of doing things and relax a bit. The first step is to realize you are burnt out and as for second, I might recommend doing these.
Additionally, I’m aware that my productive mindset is pretty welcoming to burnout. Read more about it here: https://blog.orhun.dev/open-source-grindset/
Where do you see the project heading next?
I’m hoping that more people will gain awareness about conventional commits, try out git-cliff and see how git-cliff can be useful for their specific use case. I think the project will get more exposure and catch more eyes with the upcoming features. In the meantime I will keep improving it, adding new features and fixing bugs.
In the Rust community, I’m expecting more release-oriented projects to integrate git-cliff since it can also be used as a library. For example, recently I came across release-plz which is a release helper for Rust projects.
What motivates you to continue contributing to git-cliff?
The feedback is so important. When I see people using git-cliff and reporting issues, I feel like it is my responsibility to work on the project. I know that it is not true that I have to keep maintaining it but I currently really enjoy it. It has shown me different depths of technical topics and I surely learned a lot from coding/people so in the long term I believe that I can benefit from it. Plus, before everything, people use it and it is an awesome feeling to build something useful.
Are there any other projects besides git-cliff that you’re working on?
I always try to keep myself busy with open source so there is always something that I’m working on. Currently, I’m maintaining gpg-tui, menyoki, systeroid, kmon, rustypaste, CoolModFiles.com, and various other projects. I’m also actively building a notification daemon called runst. Plus there is so much to come!
Where do you see software development heading next?
I see the current state of the software development industry as heavily evolving towards depending on front-end tools and frameworks. On the side, there are different attempts at bringing Rust/Zig into the scene but in the short term, it doesn’t look like we will get rid of legacy runtimes which contain apparent security issues and optimization problems. However, it’s good to see that there are different projects coming up every now and then and trying to improve some things. Also, cloud adoption seems highly valuable these days and cloud-native gains importance as more services are deployed with kubernetes stack.
Where do you see open-source heading next?
I think the importance of open source is increasing day by day with more companies adopting open source approaches in their products and supporting open source projects via their contributions/donations. As the open source community, we are already aware of the power of open source and it is good to see that more people are realizing how important it is. We already saw a major example such as the Apache Log4J attack in the past years. And for the next few years, I think open source will gain more attraction from different sources and it will be possible for more people to live off by just doing open source. I’m rooting for it!
Want to join the conversation about one of the projects featured this week? Drop a comment, or see what others are saying!